 Создать
Создать Новости
Новости Форум
Форум События
События Викистатьи
Викистатьи Регистрация
Регистрация Вход
Вход
Поделитесь вашим контентом. Начните с пункта меню "Создать". Большинство элементов в нём можно размещать без регистрации. И если Вы разместили действительно полезный контент, то после модерации он попадет на все информационные площадки Гильдии Маркетологов и в почтовые рассылки. Все размещенные материалы сохраняются и каталогизируются.
Если Вы решили создать свой блог на инфопортале, то для выделения Вам форума и получения прав модератора свяжитесь с администратором
Как мы научились с математической точностью отслеживать зарождающиеся тренды
Инфопортал Гильдии Маркетологов :: Новости и обзоры :: Актуальные публикации для маркетолога и рекламиста :: Материалы конференций, форумов, мнения экспертов
![]()
![]()
![]()
 Как мы научились с математической точностью отслеживать зарождающиеся тренды
Как мы научились с математической точностью отслеживать зарождающиеся тренды
![]() автор Admin Чт 11 Окт 2018, 17:08
автор Admin Чт 11 Окт 2018, 17:08

Виктор Делисов, Senior Data Analyst «АДВ Лаб», рассказывает о том, почему для брендов сейчас критически важно «быть на хайпе» и что из себя представляет технология, способная этот самый хайп поймать.
Зачем это нужно
Информационный поток движется с чудовищной скоростью – я думаю, каждый из нас своими глазами видит, как эта скорость увеличивается с каждым днем. Контента становится всё больше, информация – всё доступнее, и в этом водовороте смыслов людям чрезвычайно сложно разглядеть отдельную компанию или бренд.
Чтобы ваш продукт (будь то обезжиренный йогурт, кроссовки или сервис заказа такси) смог выделиться среди других, важно быть в тренде – уметь подхватить животрепещущую тему и эффективно использовать её в коммуникации с аудиторией.
Однако то, что было модным буквально вчера, сегодня уже неактуально, а то, о чем все говорят в данный момент, завтра может не иметь никакого значения. Один неверный шаг, и вы рискуете многократно усугубить свое положение – примеров неудачного использования «хайповых» тем в медиаиндустрии более чем достаточно.
Выход из ситуации лежит на стыке маркетинга и технологий: это возможность не просто отслеживать и анализировать ключевые темы, обсуждаемые в информационном поле, но и оценивать их вирусный потенциал и предсказывать тренд ещё на этапе его зарождения.
Немного предыстории
Наша компания является чем-то вроде «стартапа внутри корпорации» и специализируется на разработке инновационных решений для агентств крупного рекламного холдинга – то, что сейчас принято называть MarTech.
Одно из портфельных агентств группы, Initiative, обратилось к нам с задачей разработать технологию, которая бы отслеживала самые обсуждаемые темы в социальных сетях еще на этапе роста их популярности. Это позволило бы коллегам расширить свои возможности для более эффективной и «естественной» интеграции брендов клиентов в социально-культурный контекст. Проще говоря, необходим был продукт, который поможет отслеживать «новые веяния» для создания актуального контента.
Результатом нашей совместной работы стал онлайн-инструмент под названием Hype Seismometer – сервис на базе мессенджера Telegram, формирующий рейтинг самых обсуждаемых тем в режиме реального времени.
От VK к Telegram
Было очевидно, что продукт следует строить на основе семантического анализа (подразумевает работу с текстом, анализ смысловых конструкций внутри него), поэтому в первую очередь необходимо было выбрать социальную сеть с наиболее подходящими нам данными. Выбор стоял между VK и Telegram, так как основная часть данных в Instagram – графическая, а аудитория русскоязычного Facebook не так велика по сравнению с VK, сосредоточена в больших городах и имеет довольно специфичный набор предпочитаемых тем.
Сначала мы выбрали VK из-за отличного API и огромной аудитории, но результаты анализа показали, что около 67% постов в рамках одной тематики дублируют друг друга. С учетом стоящих перед нами задач это означало большие потери данных – прежде всего, косвенных данных (например, отсылки к другим событиям, произошедшим в этот же день, тональность сообщений и так далее).
Объясню на примере: допустим, вы опрашиваете десять свидетелей правонарушения, и, в сущности, все они говорят вам одно и то же. Однако каждый из них делает это по-разному: кто-то вспоминает броскую деталь во внешности нарушителя, кому-то запомнился тембр его голоса, а кто-то заметил следы, которых раньше не было. В итоге вы по крупицам собираете цельную картину происходящего. Однако если бы все свидетели буквально говорили вам одно и то же, вы бы наверняка многое упустили.
Кроме того, большое количество рекламных постов всегда осложняет сбор информации из любой социальной сети.
Тогда наше внимание привлек Telegram, успевший стать чем-то вроде современной блог-платформы. На этот раз мы остались довольны аналогичным анализом контента мессенджера: только 21% постов в Telegram оказались заимствованными, в нем пока еще немного рекламы, а также есть разбивка на тематики и все необходимые метрики для дальнейшего анализа (количество просмотров поста, количество подписчиков, Engagement Rate и прочее).
Сбор данных
В качестве источника данных мы использовали сайт-агрегатор tgstat.ru: он собирает последние 20 постов из Telegram-канала и дает описание ключевых метрик.
Мы должны были заранее определить для себя модель, с помощью которой хотим измерять тренды, смотреть пути и скорости их распространения. Для этой работы идеально подходит теория графов и топологический анализ.
Любую социальную сеть можно представить в виде так называемого «графа», то есть в виде узлов и ребер, соединяющих эти узлы. Каждый узел представляет собой канал, а ребро, соединяющее два узла – информацию, которой обмениваются каналы. Размер узла будет зависеть от количества подписчиков, а ширина ребра – от того объема информации, который протекает между ними.

И раз уж мы работаем с семантикой, нам также необходима единица измерения, позволяющая понять, о чем именно идет речь в конкретном посте. Такой единицей являются биграммы – словосочетания, содержащие минимальную смысловую нагрузку, необходимую для определения связи поста с той или иной темой. Например, во фразе «мама мыла раму» есть три биграммы: «мама мыла», «мыла раму» и «мама раму». Каждой из этих биграмм присваиваются все атрибуты, которые описывают сам пост.
Работа с данными
Чтобы перед нами не оказалась огромная безликая сеть из десятков тысяч каналов, была проведена предварительная фильтрация по следующим параметрам:
- каналы только на русском языке;
- каналы с количеством подписчиков более 200;
- каналы с ER более 50%.
Таким образом мы сократили 50 000+ каналов до 17 000.
Кроме того, необходимо было отсечь информационные тупики – каналы, повышающие охват за счет взаимного репостинга 100% контента друг друга. Как правило, они объединяются в небольшие группы и по всем показателям быстро распространяют информацию, однако на самом деле их емкость конечна и легко достигает насыщения.
Этого удалось добиться путем разделения всех каналов на четыре категории на уровне структуры графа:
- Каналы, находящиеся ближе к центру графа (то есть с большим количеством связей), более склонные к созданию собственного контента.
- Каналы, находящиеся ближе к центру графа (то есть с большим количеством связей), более склонные к репостингу.
- Каналы, находящиеся на краю графа и образующие собственные замкнутые системы (информационные тупики).
- Каналы, являющиеся полными одиночками.
Так как наша цель – ловить тренды, для нас критически важной является скорость распространения новости – метрика, более известная как скорость реакции сети (аналогичную технологию использует Twitter). В каждой категории этот показатель будет отличаться – например, в каналах, посвященных экономике, скорость распространения информации будет ниже, чем в каналах, посвященных криптовалютам.
Однако разбивки по категориям недостаточно – в каждой категории присутствует довольно много каналов, которые выбиваются из общей тенденции. Для решения этой проблемы в дело вступает кластерный анализ – по сути, классификация по типу поведения, которую можно условно представить в виде следующей формулы:
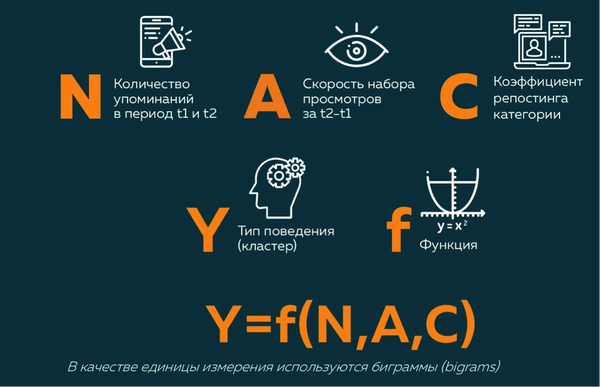
В результате мы получили 16 кластеров, позволяющих нам оценить каналы именно с точки зрения скорости распространения информации. На основании кластера, в котором оказался тот или иной канал, каждый пост внутри него получает свой коэффициент, который затем поступает в формулу расчета веса этого поста среди всех постов в Telegram. Делать это вручную было бы самоубийством, поэтому здесь бесценную службу нам сослужило машинное обучение.
Что мы получили в итоге
Прозвучит забавно, но весь этот сложный механизм укладывается в Telegram-бота, подключенного к удаленным базам данных, в которых и проводятся все расчеты. Бот в удобном для пользователя формате выдает информацию о самых популярных темах в нужной категории за последние сутки, неделю или месяц.
Проект был официально запущен совсем недавно, поэтому провести преднамеренное тестирование его способности выявлять хайп пока сложно – как ни крути, но для подобного теста нужно заранее знать, какая тема окажется в тренде, а если бы кто-то это умел, необходимости выводить на рынок подобный продукт не было бы Однако мы провели замеры релевантности поисковой выдачи и получили довольно убедительные доказательства эффективной работы бота:
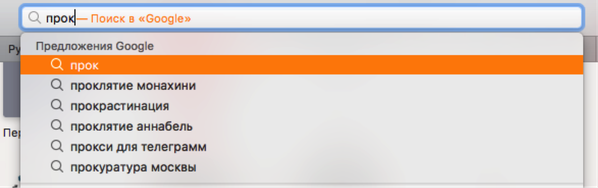
- Первый замер был проведен в категории «Видео и фильмы» за период с 24 сентября по 1 октября. Согласно выдаче Hype Seismometer, самой популярной темой для обсуждения оказался фильм «Проклятие монахини». Сравнив эти данные с поисковой выдачей Google и «Яндекс» за аналогичный период, мы получили более 115 тысяч результатов по теме в Google в разделе «Новости», а также более 220 сообщений по теме в «Яндексе».
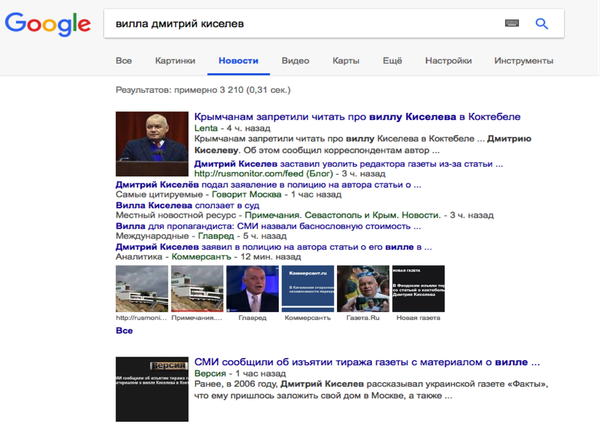
- Гораздо более важным оказался перекрестный замер по всем категориям. Здесь мы рассматривали данные за отдельно взятые сутки (30 сентября). В результате самой популярной темой была определена новость о вилле Дмитрия Киселева в Крыму.
Сверив полученные данные с поисковой выдачей Google в разделе «Новости», мы обнаружили более 3200 результатов по теме за сутки.
Таким образом, мы весьма оптимистично настроены на проведение первых SMM-кампаний с использованием результатов работы технологии и надеемся, что уже в ближайшее время у нас появятся практические кейсы, которые помогут более наглядно продемонстрировать её эффективность.
Кейс был представлен на Big Data Conference.
Автор: Виктор Делисов, Senior Data Analyst в «АДВ Лаб»
Источник: https://rb.ru/opinion/martech-advlab/
Admin- Admin
- Дата регистрации : 2016-02-14
Сообщения : 836
Репутация : 17
![]()
![]()
![]()
![]()
![]()

 Похожие темы
Похожие темы» Как гуманитариям понять смысл математической статистики? Да просто ... посмотреть на Петродворец!
» Традиции и тренды питания россиян
» Тренды медицинского маркетинга на 2019 год
» Тренды индустрии: фрукты и овощи
Инфопортал Гильдии Маркетологов :: Новости и обзоры :: Актуальные публикации для маркетолога и рекламиста :: Материалы конференций, форумов, мнения экспертов